
Neural Radiance Fields (NeRF) has achieved unprecedented view synthesis quality using coordinate-based neural scene representations. However, NeRF's view dependency can only handle simple reflections like highlights but cannot deal with complex reflections such as those from glass and mirrors. In these scenarios, NeRF models the virtual image as real geometries which leads to inaccurate depth estimation, and produces blurry renderings when the multi-view consistency is violated as the reflected objects may only be seen under some of the viewpoints. To overcome these issues, we introduce NeRFReN, which is built upon NeRF to model scenes with reflections. Specifically, we propose to split a scene into transmitted and reflected components, and model the two components with separate neural radiance fields. Considering that this decomposition is highly under-constrained, we exploit geometric priors and apply carefully-designed training strategies to achieve reasonable decomposition results. Experiments on various self-captured scenes show that our method achieves high-quality novel view synthesis and physically sound depth estimation results while enabling scene editing applications.
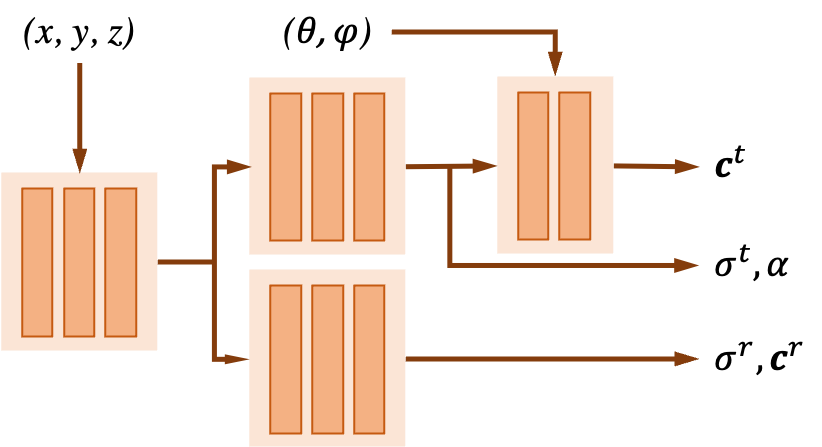
Instead of representing the whole scene with a single neural radiance field, we propose to model the transmitted and reflected parts of the scene with separate neural radiance fields. To synthesize novel views, the transmitted image \(I_t\) and reflected image \(I_r\) rendered by the corresponding fields are composed in an additive fashion, where the reflected image \(I_r\) is weighted by a learned reflection fraction map \(\mathbf{\beta}\): \[I = I_t + \mathbf{\beta} I_r\] The network architecture is illustrated as follow:
NeRFReN is able to split the scene into transmitted and reflected components and estimate physically more correct depth (column 3) due to this decomposition. Novel views (column 1) can be synthesized by combining the transmitted (column 2) and reflected (column 5) images by the predicted reflection fraction map (column 4).
Compared with NeRF (right), NeRFReN (left) can achieve promising view synthesis results with more correct depth estimation. Benefit from the separate modeling of transmitted and reflected components, NeRFReN can handle hard cases like the mirror scene, where NeRF cannot synthesize correct views for some viewing directions.
Our formulation naturally supports the application for reflection removal by taking only the transmitted image (see column 3 of the decomposition results). We can also achieve reflection substitution by replacing the reflection image \(I_r\) by images coming from other neural radiance fields, or even from other scene representations like mesh. Here shows two examples of replacing the reflections with images rendered from another NeRF model trained on the room scene of the LLFF dataset. This could be further promoted to synthesize self-reflections of the user to provide even more immersive experiences.

@InProceedings{Guo_2022_CVPR,
author = {Guo, Yuan-Chen and Kang, Di and Bao, Linchao and He, Yu and Zhang, Song-Hai},
title = {NeRFReN: Neural Radiance Fields With Reflections},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {18409-18418}
}